<tfoot id="wwqb6"><rp id="wwqb6"></rp></tfoot>
如若轉載,請注明出處:http://www.qshczs.cn/product/58.html
更新時間:2026-06-07 20:06:25
產品包裝 禮盒設計 互聯網企業
帶蓋子的禮品盒模切圖 刀模圖eps源文件 平面素材 美工云 meigongyun.com 未歸類
手提禮盒包裝圖片 手提禮盒包裝設計素材 紅動中國
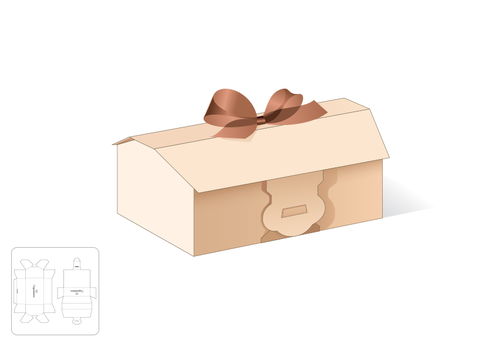
房屋形狀禮品盒模切圖 刀模圖eps源文件 平面素材 美工云 meigongyun.com 未歸類
北京大興熏香木盒的價格 瑞勝達木盒工廠
彩妝大牌丨吶~你要的2018圣誕限定都在這里了!
陜西禮品盒廠家批發,無論你的需求是什么,賽爾富都能完美匹配
圖 北京茶葉木盒供應商,木盒禮品盒,完善售后服務 北京印刷包裝
古象大酒店金秋推出豪華月餅禮盒
金絲帶禮品盒
地址:山東省聊城市東昌府區廣平鄉北賈村39號
Copyright © 2026 www.qshczs.cn 禮品盒 聊城信宇包裝有限公司 禮品盒 版權所有 Sitemap